Hello, Ollama 👋
We’ve gone from “hello world” to “hello, full-blown language model on my terminal” way too fast.
How cool is it that you can now run LLMs locally on your machine?
And honestly? I Oollaammaa the ability to mess around with models right from the terminal.
Feels like Matrix Reloaded, 2025 edition. Yes, I still reference The Matrix—it’s a masterpiece, fight me. 😎
Why Ollama? 🤔
Because it makes running local LLMs dumb easy. Just you, your terminal, and an LLM ready to jam.
But the real magic? Running it locally means:
- 🔒 Privacy — nothing you type goes to the cloud.
- 🚫 Offline Access — no internet? No problem.
- ⚡ Speed — models respond faster without roundtrips to a server.
- 🧪 Total Control — switch models, fine-tune, or even build your own.
- 🔋 Resource Efficiency — optimized to run on M1/M2 Macs, no beefy GPUs needed.
Whether you’re prototyping ideas, crafting AI masterpieces, or just curious—Ollama gets out of your way and lets you experiment without limits.
Let’s Get Started 🚀
Here’s how you can get Ollama running on your Mac in minutes (I’m talking only about Mac for now—it’s every dev’s dojo 🖥️🍎, isn’t it? 😎🚀):
Install
brew install ollamaRun
My personal favorite … phi4
ollama run phi4Now you should see a slick terminal interface—ask away all your questions, mess around, go wild. 🧙
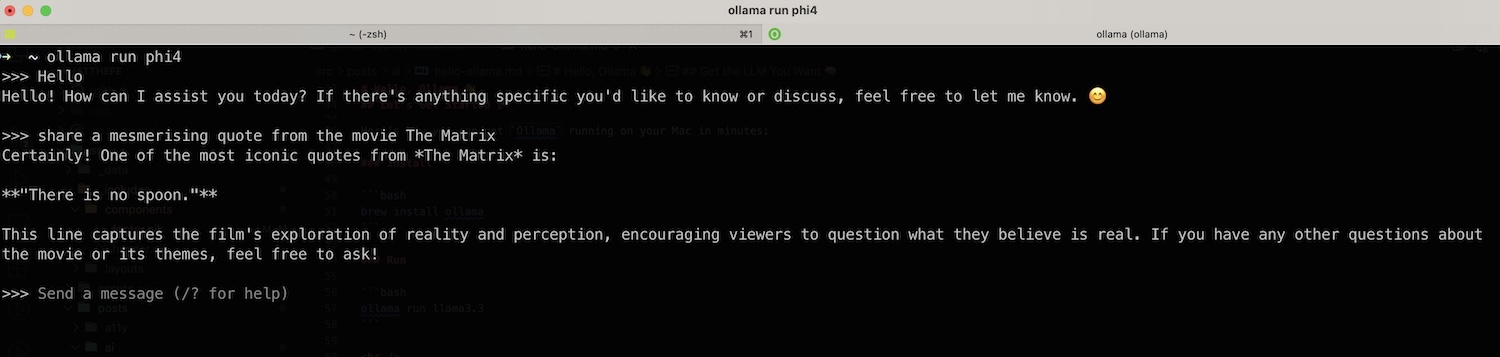
And boom 💥 you’re talking to phi4, one of the latest models—locally.
I don’t think it gets any simpler than that.
It’s fast, works ridiculously well, and some models are specially optimized for local use.
At this point, I have no more words… I feel like I’m plugged into the Matrix—just code, coffee, and endless possibilities. 💻⚡
Get the LLM You Want 🧠
There are tons of models—big, small, mini, for embeddings, and probably a bunch I have no clue what they’re built for or what they even do. But they’re just chillin’ there, waiting for you to poke around and unleash some wild AI chaos. Just search for the model you want here: LLMs models, and run it.
ollama run phi4After messing around with a bunch of models, you’ll probably wanna know what you’ve got locally?
Run:
ollama listSome Useful Ollama CMDs 🛠️
ollama list # List downloaded models
ollama ps # List running models
ollama show # Show information for a model
ollama pull phi3 # Pull model from registry
ollama run llama2 # Run a model
ollama stop # Stop a running modelOpen-WebUI Interface? Yes Please 🖥️🔥
Sure, the terminal’s great for street cred and privacy… But sometimes, you just want to kick back with a browser-based UI.
There are a few options to choose from: Docker Hub - Open WebUI.
This one worked well for me:
docker run -d \
--name open-webui-dyrnq-v3 \
-p 9090:8080 \
--add-host=host.docker.internal:host-gateway \
-v $HOME/dev/docker-volumes/open-webui-data:/data \
dyrnq/open-webuiThen just head to http://localhost:9090.
Browse models, fire off prompts, and let the local magic happen.
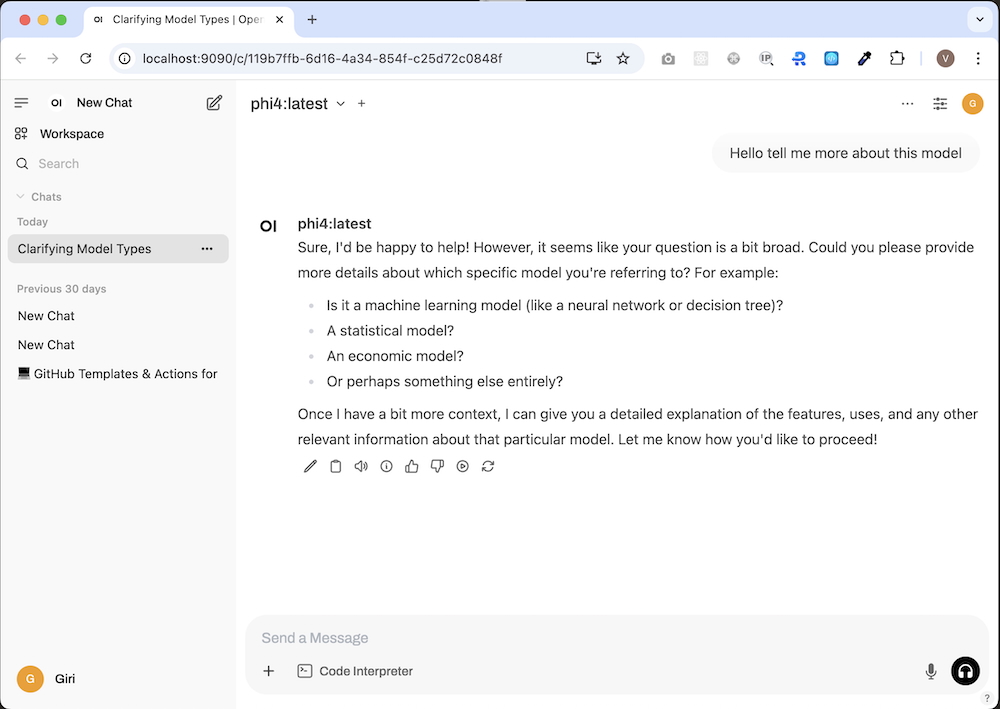
What’s Next?
This got me so hyped, I’m already cooking up some mad experiments.
Can’t say more just yet… but something rad is on the way. 👀
Until then… ✌️ Peace out.✌️ dev-verse explorers
Welcome to the era of local AI.
Probably I’m already late and feeling old—but hey, at least I showed up. 😅🤖

Join the discussion:
Got thoughts on this post or anything else in the WTFe.dev universe? 🤔 Let's discuss